學習,從複製開始
 筆者有話先說
筆者有話先說有了 Facebook 爬蟲的經驗後,我相信這篇大家是有能力獨自完成的,建議大家先用自己的方式來完成今日目標,這篇文章適合實作遇到問題或是你實作完成後再來參考
 今日目標
今日目標1.1 分析 IG 登入頁面的元件
1.2 改用 css 抓取元件,完成 IG 自動登入
3.1 了解響應式網頁對爬蟲的影響
3.2 設定瀏覽器開啟時的視窗大小
3.3 完成前往 IG 帳號並取得追蹤人數的程式
我在反覆使用 IG 登入 時發現登入的畫面偶爾會長不一樣(如下圖)導致Xpath路徑錯誤
| 版本1 | 版本2 |
|---|
 |
|
先進入開發者模式確認紅框內元件的特徵

input 的 html 標籤
name 這個 attribute 來表示他們的作用

button 的 html 標籤
type 這個 attribute 來表示他要執行的動作
改用 css 抓取 IG 登入的元件來操作
//填入ig登入資訊
let ig_username_ele = await driver.wait(until.elementLocated(By.css("input[name='username']")));
ig_username_ele.sendKeys(ig_username)
let ig_password_ele = await driver.wait(until.elementLocated(By.css("input[name='password']")));
ig_password_ele.sendKeys(ig_userpass)
//抓到登入按鈕然後點擊
const login_elem = await driver.wait(until.elementLocated(By.css("button[type='submit']")))
login_elem.click()
- 別忘記在 .env檔填寫 IG登入的帳號密碼
#填寫自己登入IG的真實資訊(建議開小帳號來實驗,因為帳號使用太頻繁會被官方鎖住) IG_USERNAME='ig username' IG_PASSWORD='ig password'
IG 要登入之後才會有右上角功能列,這裡我使用他作為判斷登入與否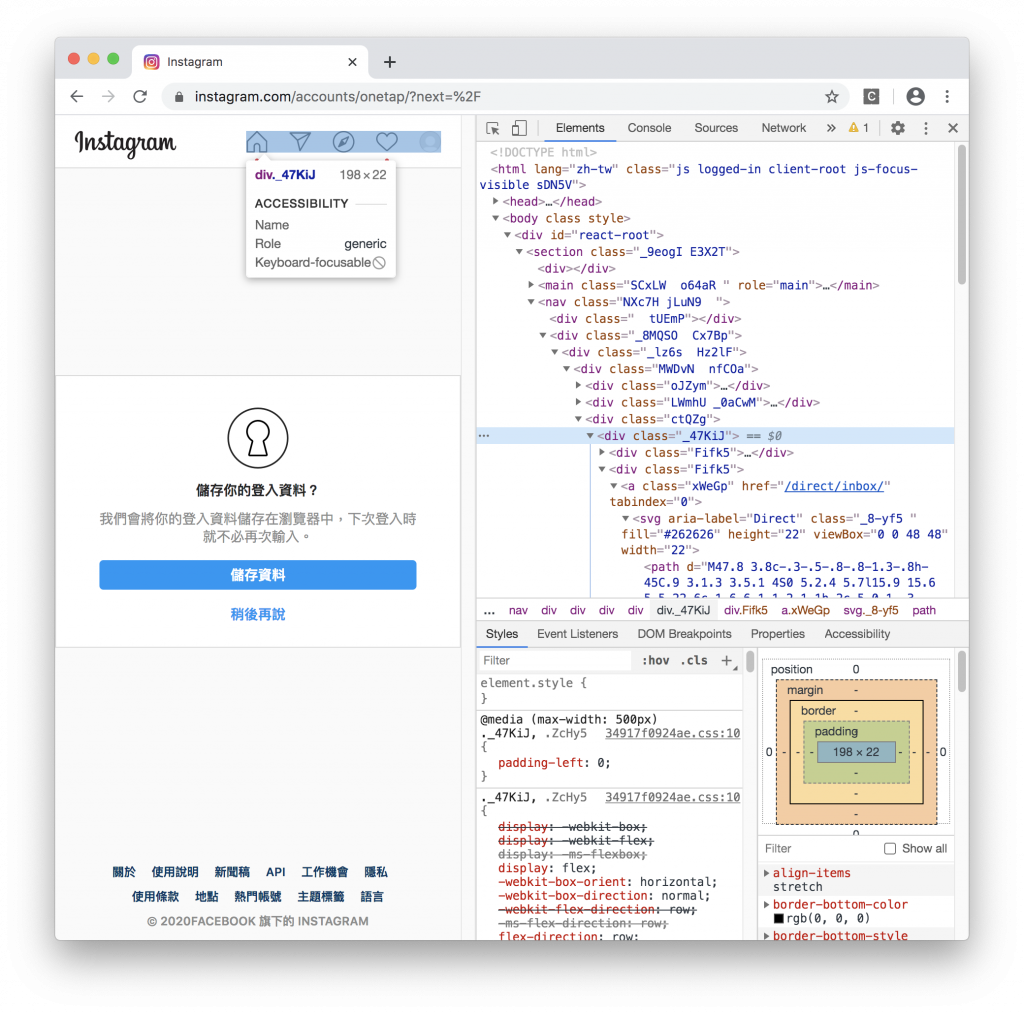
//登入後才會有右上角功能列,我們以這個來判斷是否登入
await driver.wait(until.elementLocated(By.xpath(`//*[@id="react-root"]//*[contains(@class,"_47KiJ")]`)))
IG 的頁面會隨著螢幕寬度更改而重新排版,Xpath 的路徑也會跟著改變

//*[@id="react-root"]/section/main/div/header/section/ul/li[2]/a/span

//*[@id="react-root"]/section/main/div/ul/li[2]/a/span
設定瀏覽器開啟時的視窗大小(本專案以寬螢幕作為範例),這樣才能保證你的爬蟲在不同電腦有一樣的執行結果
// 建立browser的類型
let driver = await new webdriver.Builder().forBrowser("chrome").withCapabilities(options).build();
//考慮到ig在不同螢幕寬度時的Xpath不一樣,所以我們要在這裡設定統一的視窗大小
await driver.manage().window().setRect({ width: 1280, height: 800, x: 0, y: 0 });
//登入成功後要前往粉專頁面
const fanpage = "https://www.instagram.com/baobaonevertell/"
await driver.get(fanpage)
await driver.sleep(3000)
let ig_trace = 0;//這是紀錄IG追蹤人數
const ig_trace_xpath = `//*[@id="react-root"]/section/main/div/header/section/ul/li[2]/a/span`
const ig_trace_ele = await driver.wait(until.elementLocated(By.xpath(ig_trace_xpath)))
// ig因為當人數破萬時文字不會顯示,所以改抓title
ig_trace = await ig_trace_ele.getAttribute('title')
console.log(`追蹤人數:${ig_trace}`)
driver.quit();
 執行程式
執行程式yarn start

到目前為止我們已經可以抓出 FB & IG 粉專的追蹤人數了,充滿好奇心的讀者可以先試著看看利用爬蟲爬完 FB 粉專後繼續爬 IG
 參考資源
參考資源免責聲明:文章技術僅抓取公開數據作爲研究,任何組織和個人不得以此技術盜取他人智慧財產、造成網站損害,否則一切后果由該組織或個人承擔。作者不承擔任何法律及連帶責任!
我在 Medium 平台 也分享了許多技術文章
❝ 主題涵蓋「MIS & DEVOPS、資料庫、前端、後端、MICROSFT 365、GOOGLE 雲端應用、個人研究」希望可以幫助遇到相同問題、想自我成長的人。❞
在許多人的幫助下,本系列文章已出版成書,並添加了新的篇章與細節補充:
- 加入更多實務經驗,用完整的開發流程讓讀者了解專案每個階段要注意的事項
- 將爬蟲的步驟與技巧做更詳細的說明,讓讀者可以輕鬆入門
- 調整專案架構
- 優化爬蟲程式,以更廣的視角來擷取網頁資訊
- 增加資料驗證、錯誤通知等功能,讓爬蟲執行遇到問題時可以第一時間通知使用者
- 排程部分改用 node-schedule & pm2 的組合,讓讀者可以輕鬆管理專案程序並獲得更精確的 log 資訊
有興趣的朋友可以到天瓏書局選購,感謝大家的支持。
購書連結:https://www.tenlong.com.tw/products/9789864348008


